
自宅PCで生成AI(ローカルLLM)の動かし方
ChatGPTのような生成AIを、自宅PCで動かせる「ローカルLLM」が注目されています。
高性能GPUを搭載したPCがあれば、オフライン環境でもAIチャットや音声認識、画像解析などを楽しめます。
しかし、実際に導入しようとすると、CUDA・GPU・VRAM・量子化モデル・Python環境など、初心者がつまずきやすいポイントが数多くあります。
私自身も、
「GPUで動かない」
「異常に遅い」
「ライブラリの依存関係でエラーになる」
といった問題に何度も苦戦しました。
この記事では、実際の導入経験をもとに、ローカルLLM構築時につまずきやすいポイントや、失敗しにくい構成を分かりやすく解説します。
この記事でできること
- ChatGPTのような生成AIを自宅PCで動かせる
- GPUを使って高速にAIを動作できる
- オフライン環境でAIを利用できる
- NVIDIA RTXシリーズで動作可能
- ローカルLLM環境の構築方法がわかる
※初心者向けに、CUDA・GPU・モデル選定についても解説します。
前提条件
- gemma 2を利用したローカルLLMの構築方法を解説します。
- LLMの実行環境はllama cpp pythonです。
- NVIDIA GPU RTXシリーズ等を搭載したPCが必要です。
- OSはWindowsベースで解説します。
GPU搭載のPCにご興味のある方は、この記事の最後に選定方法を紹介していますので、ご確認ください。
ローカルLLMモデルの選び方
GPUメモリの確認
お使いのGPUメモリによって、利用できるモデルに制限があるため、まずはGPUメモリの確認方法について、紹介します。
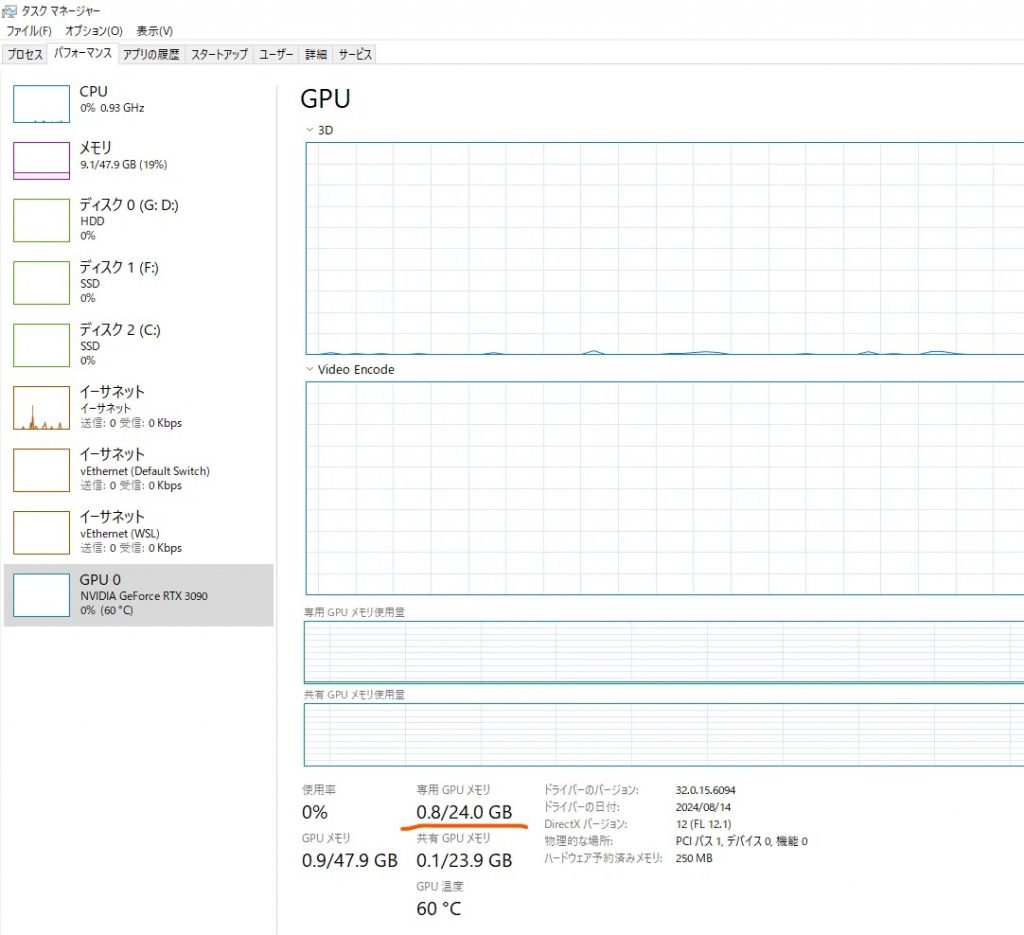
タスクマネージャー > パフォーマンス > GPU
からGPUメモリ(専用メモリ)が確認できます。(共用メモリは不可です。)
これが使用可能なモデルサイズとなります。
私のPCだとGPUメモリは下記のとおり24GBです。
搭載可能なモデルの目安
LLMのモデルには、gemma 2-27B-itのように「8B」や「27B」、「70B」といった記載があり、モデルのサイズを〇〇Bと表現しています。
これらの意味は、LLMモデルがそれぞれ80億個、270億個、700億個のパラメータによって表現されていることを意味し、基本的にパラメータ数が多いほど性能が高くなります。
ただし、その分だけ必要なGPUメモリも増加します。
目安として、GPUの必要メモリは「モデルサイズ × 2」です。
- 8Bモデル→約16GB
- 27Bモデル→約54G
- 70Bモデル→約140GB
このままでは必要なメモリサイズは大きくなってしまうため、量子化というモデルを軽量化する技術を利用します。
「量子化(Quantization)」を使うと、性能を少し抑える代わりに必要メモリを大幅に削減できます。
例えば、「Q4_K_M」形式では、メモリ使用量を約1/4に抑えることが可能です。
よって、量子化モデルを使う場合は、以下がGPUのメモリサイズの目安となります。
モデルサイズ 〇B × 2 ÷ 4= GPUメモリサイズ 〇 GB
本記事では量子化モデルを利用するため、下記が目安となります。
(公式でも量子化済みのモデルは多々あります。)
- 8Bモデル→約4GB
- 27Bモデル→約13.5GB
- 70Bモデル→約35GB
モデルのダウンロード方法
Huging Faceに登録
オープンソースの生成AIが多数登録されているHuging Faceというサイトからモデルをダウンロードします。
ユーザー登録が必要なので、下記公式サイトから登録してください。(無料です。)

モデルのダウンロード
Hugging FaceにGoogleがモデルを提供しているページがあり、そこからご自分の環境に合わせたモデルをダウンロードできます。
今回は、GoogleのオープンソースAIであるgemma 2を使うのですが、gemma2に関してはggufの提供がないため、grapevine-AIさんが日本後重視で変換されたモデルがおすすめです。
ちなみにgemma 3はGoogleのページにggufモデルが提供されていますが、こちらはマルチモーダルLLM(画像も扱えるLLM)なので、ひと手間必要になります。
そちらは別記事で解説予定です。
お使いのGPUメモリに合わせて、以下のモデルをダウンロードしてください。
GPUメモリが8GBの場合の推奨モデル
gemma-2-9b-it-Q4_K_M.gguf

GPUメモリが24GBの場合の推奨モデル
gemma-2-27b-it-Q4_K_M.gguf

Visual Studioのインストール
CUDAのインストール時にBuild Tools for Visual Studioが必要になるので、事前にインストールします。
以下のサイトからそのままVisual Studio(community)を入れてもOKですが、必要部分のみとしたい方は、Build Tools for Visual Studioのみインストールできます。
今回は、Build Tools for Visual Studioのみインストールする方法について、説明します。
1.以下サイトに移動

2.ページを下の方にスクロール
3.Tools for Visual StudioのBuild Tools for Visual Studio 2026をダウンロード
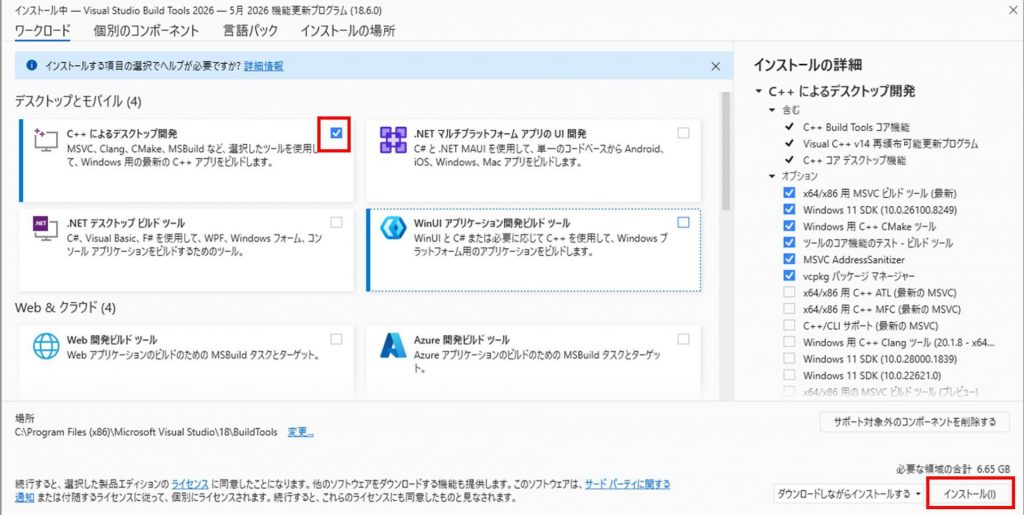
4.vs_BuildTools.exeを実行し、「C++によるデスクトップ開発」にチェックを入れインストールを実行します。(環境によりますが、数時間程度かかる場合があるので、気長に待ちましょう。)
NVIDIAドライバーのインストール
対応ドライバーの確認&インストール方法
下記サイトからNVIDIAドライバーの最新版をインストールします。
ご自宅のGPU環境を選択するとダウンロードできます。
私の場合は、GPU NVIDIA GeForce RTX 3090なので、下記のとおり選択します。
- 製品カテゴリ:GeForce
- 製品シリーズ:GeForce RTX 30 Series
- 製品を選択:GeForce RTX 3090
- オペレーションシステムを選択:Windows 10 64-bit
- 「探す」を押すと該当するドライバーを検索します。
- 「GeForce Game Ready ドライバー」と「NVIDIA Studio ドライバー」があるので、NVIDIA Studio ドライバーをダウンロードとして、インストールしてください。
※「GeForce Game Ready ドライバー」でもCUDA自体は利用できるため、ローカルLLMが動作する可能性は高いですが、AI・動画編集・クリエイティブ用途ではStudioドライバーの方が安定しやすいと言われています。

CUDAインストール
CUDAはGPUを利用して、高度な計算処理を行うためのアーキテクチャです。
LLMをGPUで動かしたり、その他のAIを利用する際に必須となります。
対応バージョンの確認方法
必要なCUDAのバージョンはわかりにくいのですが、Wikipediaを利用すると簡単に調べられます。
1.WikipediaのCUDAのページに移動

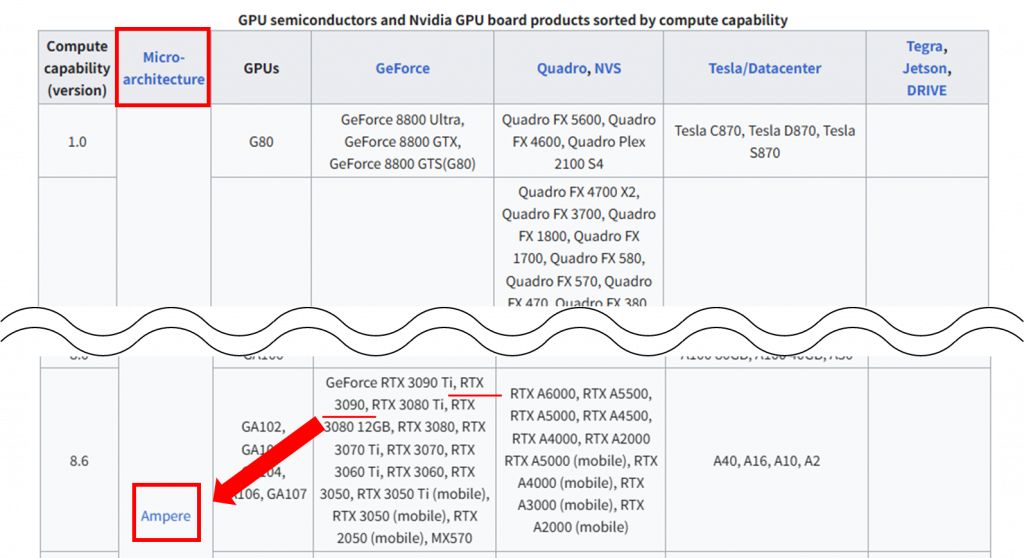
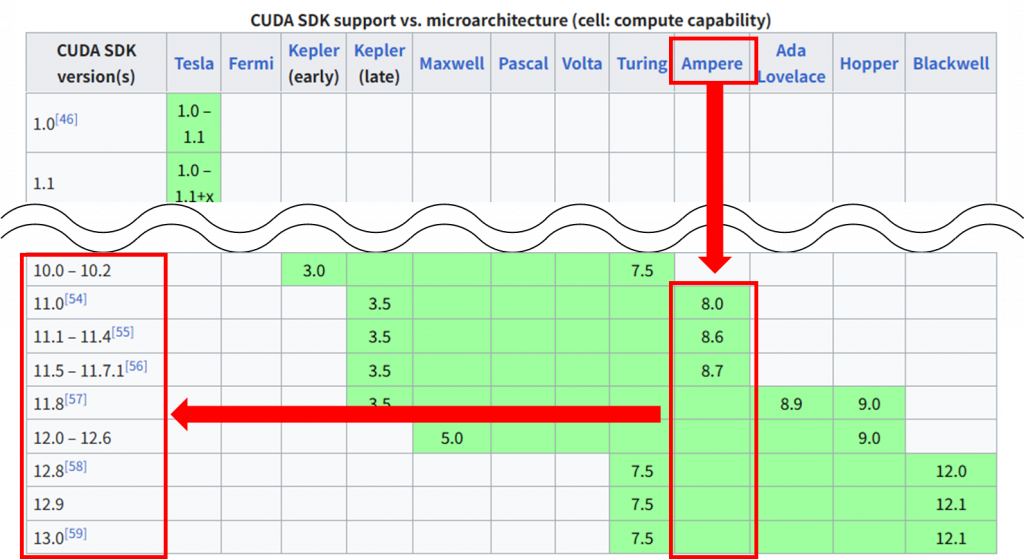
2.「GPU semiconductors and Nvidia GPU board products sorted by compute capability)」という表を確認し、ご自身のGPUの型番から「Micro architecture」を確認する
私の場合は、Geforce RTX 3090なので、「Ampere」となります。
3.同じページですが、一つ上の表「CUDA SDK support vs. microarchitecture (cell: compute capability)」を確認し、[CUDA SDK version(s)」を確認します。
背景が緑になっている箇所に対応するバージョンが利用できます。
私の場合は、「Ampere」だったので、インストール時に最新であったCUDA12.4をインストールしています。
CUDAインストール方法
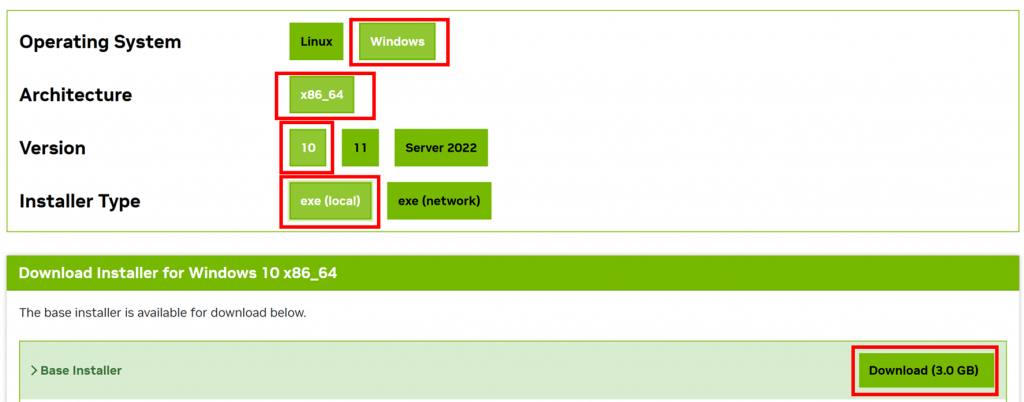
1.以下のサイトにアクセスして、対象のバージョンをクリックします。
私の場合は、12.4をインストールしているので、画像のバージョンとなります。


2.お使いのPCの環境に合わせて、選択していくとDownloadのボタンが表示されるので、ダウンロードを実行します。
3.イントーラーがダウンロードされるので、「cuda_バージョン情報_windows.exe」を実行します。
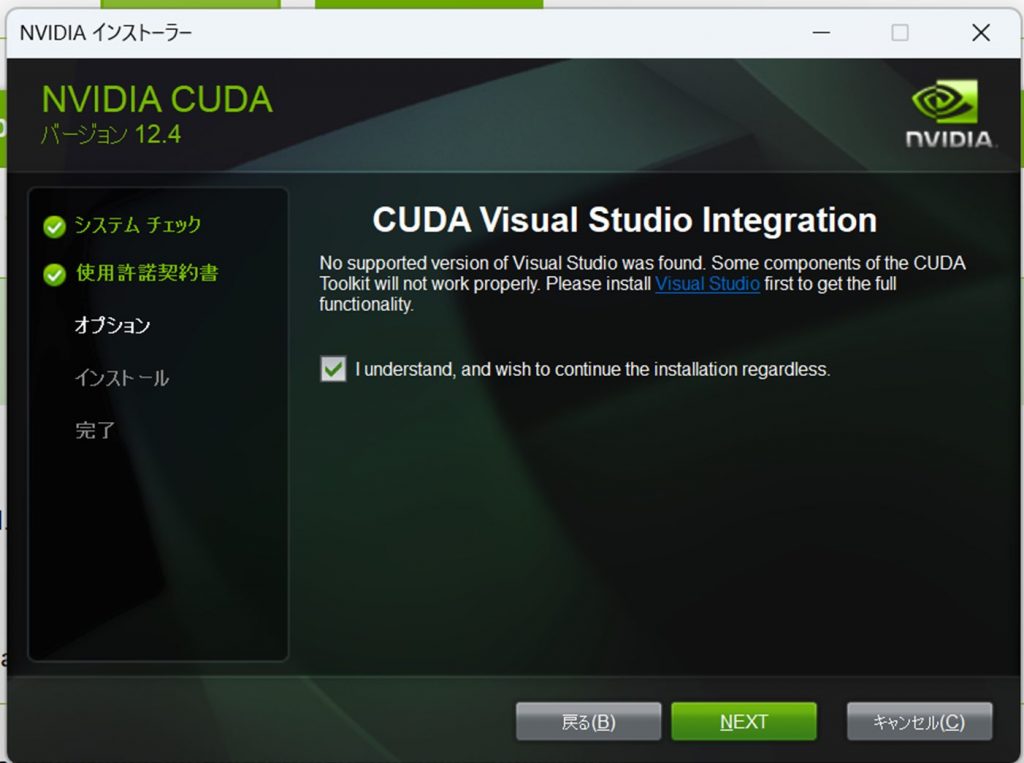
4.使用許諾契約書に「同意して続行する」をクリック。
5.高速(推奨)を選択し、次へをクリック。
6.チェックをつけて、NEXTでインストールが開始ます。
動作確認
必要ライブラリのインストール
以下のようにpip installでllama-cpp-pythonをインストールします。
cu124の部分はご自分のCUDAのバージョンに合わせてください。
私の場合はCUDA 12.4だったので、cu124となります。
python -m pip install llama-cpp-python==0.3.4 --upgrade --force-reinstall --no-cache-dir --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu124うまくインストールできない場合は、一度、手動でダウンロードして、以下のようにインストールする方法すると良いです。
python -m pip install "【保存場所】\llama_cpp_python-0.3.4-cp312-cp312-win_amd64.whl"ダウンロード先は以下です。
該当するものを選んでください。

サンプルコード
from llama_cpp import Llama
llm = Llama(
model_path=r"【任意のフォルダを指定してください】/gemma-2-9b-it-Q4_K_M.gguf",
n_gpu_layers=-1
)
while True:
text = input("You > ")
if text == "exit":
break
output = llm.create_chat_completion(
messages=[
{"role": "user", "content": text}
]
)
print("\nLLM >", output["choices"][0]["message"]["content"], "\n")
動作確認
サンプルコードを実行し、LLMと会話できるか確認します。
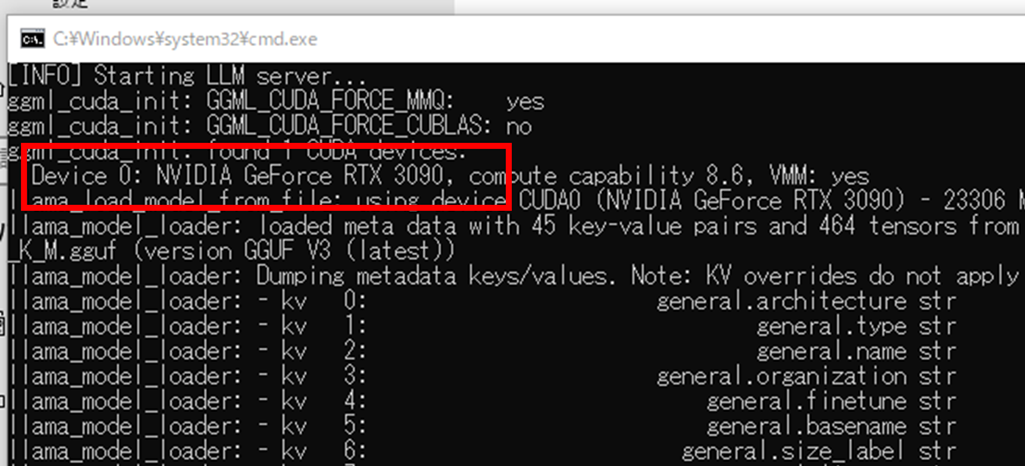
まずは画像のようにGPUが利用できているか確認してください。
「Device 0:~」の部分にお使いのGPUが表示されていればOKです。
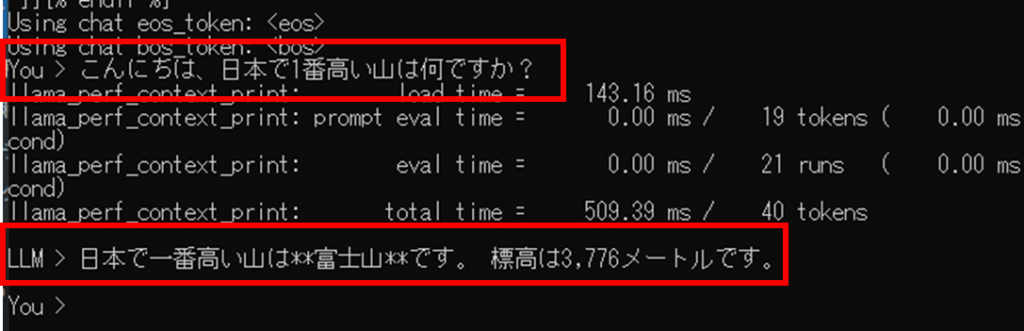
後は下の画像のように会話できれば、OKです。
GPU搭載おすすめPCの購入方法
私はFRONTIER製のPCを利用しているのですが、コストパフォーマンスが良いので、おすすめです。
ゲームもできるFRONTIER製のPCで、おすすめの構成を3つ紹介したいと思います。
①推奨品:GPUメモリ12GB
GPUメモリは12GBあると安心です。
Gemma 3 12Bは8GBでも量子化すれば動作可能ですが、かなり余裕が少なくなるので、12GB以上を推奨します。
②コスパ重視品:GPUメモリ8GB
8GBあれば、大抵のローカルLLMモデルは動きます。
しかし、メモリに余裕がないので、コスト重視の方向けです。
③上級者向け品:GPUメモリ32GB
こちらは、現在最新のRTX5090構成です。
業務用のGPUを買う猛者もいるので、予算と相談して、良いものをご購入ください。
PC検索方法
1.以下のバナーからフロンティアのサイトへ移動します。

2.良さそうなセールPCがあれば、そちらをカスタムするのが、コスパ良いです。
2026年5月 現在でいうと以下の二つがおすすめです。
RTX5060 (GPUメモリ8GB)、RTX5070 (GPUメモリ12GB)となります。

3.お気に召すものがなければ、以下のように検索アイコンをクリックして、GPUメモリを選択します。
4.絞り込み検索をクリック
5.グラフィックスの「+」マークをクリック
6.それぞれご自身のタイプ別にGPUを選択し、ヒットしたPCをカスタムしてください。
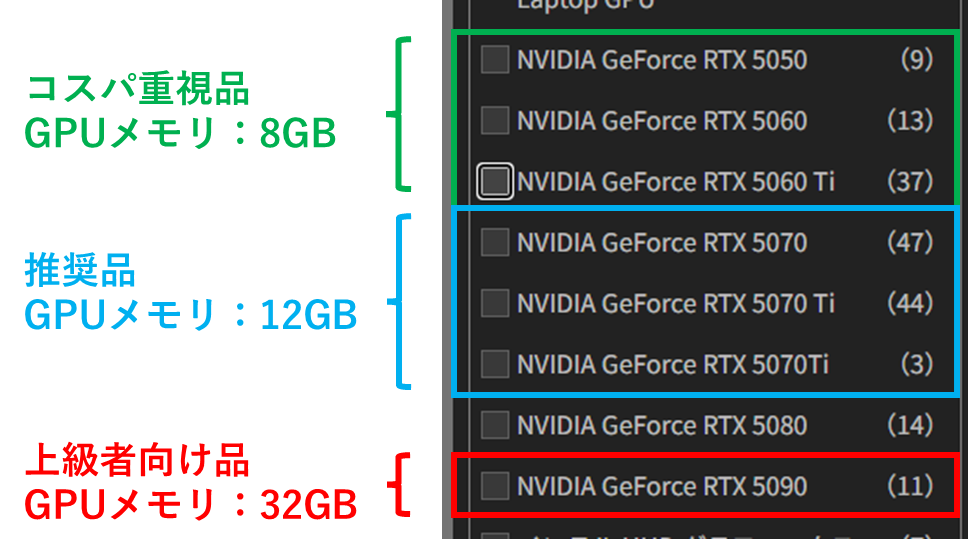
実際には、RTX 5060の中にもGPUメモリ16GBモデルがあったりするので、RTX シリーズ=GPUメモリというわけでは、ありませんが、上記のような選択で、想定するものがヒットしやすいです。
さらに、資金に余裕があれば、電源のグレードを上げることをおすすめします。
グレードを上げることで、パワー不足になりにくいので、おすすめです。
コメント